Многие считают, что собрать данные с hh.ru — задача на вечер: requests, BeautifulSoup, цикл по страницам, готово. На практике первый же запуск приносит пустые списки при ответе 200 OK, второй — бан по IP, а третий — претензию от юриста. HeadHunter — это не «обычный сайт», а крупная база с миллионами записей, регулируемая ФЗ-152 и собственным пользовательским соглашением. Дальше — последовательный разбор того, что и как собирать с площадки, какие ограничения встроены изначально, где проходит правовая красная линия и как выглядит парсер, который доживает до второго месяца эксплуатации.
Содержание
- Что такое HH.ru с точки зрения данных
- Иерархия методов: с чего начинать
- Официальный API: эндпоинты, токены, поля
- Лимиты и подводные камни
- Антибот-защита и техники обхода
- Резюме: правовая красная линия
- Архитектура промышленного парсера
- Кейсы реальных проектов
- Готовые сервисы и no-code инструменты
- Типичные ошибки и как их избежать
Что такое HH.ru с точки зрения данных
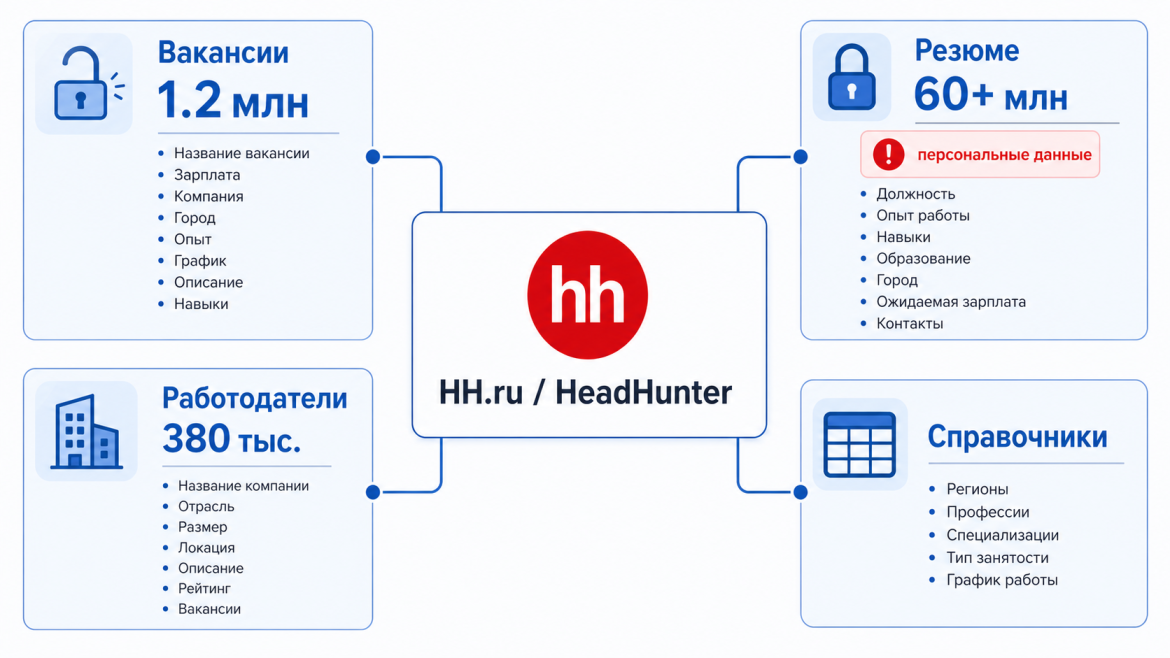
HeadHunter — крупнейшая площадка поиска работы в русскоязычном сегменте. По разным оценкам, на ней одновременно живёт от 1,1 до 1,2 млн активных вакансий, около 60–86 млн резюме и порядка 380 тысяч компаний, а ежедневно появляется примерно 25 тысяч новых вакансий. Платформа покрывает около 80% рынка СНГ, и именно поэтому она остаётся первой целью для рекрутеров, аналитиков и исследователей рынка труда. К той же экосистеме относится zarplata.ru, принадлежащая HH и работающая на тех же протоколах.
На уровне данных площадка устроена иерархично: страны, регионы, города, работодатели, вакансии, резюме, словари справочников. Для парсера это означает, что любая прикладная задача упирается в один из четырёх объектов:
- Вакансия — публичный объект, описывающий должность, работодателя, регион, вилку зарплаты, опыт, график, требования и описание;
- Резюме — частично публичный, частично закрытый объект, содержащий персональные данные;
- Работодатель — карточка компании со списком открытых вакансий и иногда рейтингом;
- Справочник — закрытые таблицы с типами занятости, профессиональными ролями, графиком и регионами.
Эта классификация важна не сама по себе. Именно от типа объекта зависит и метод сбора, и правовой режим, и допустимый объём. Вакансии можно собирать через документированный API в неограниченных по сравнению с резюме объёмах, тогда как массовый сбор резюме без согласия субъекта прямо запрещён законом.
Иерархия методов: с чего начинать
Самый дорогой по времени и поддержке способ собрать данные с HH — это парсить HTML-разметку напрямую. Даниил Охлопков в материале «Как спарсить любой сайт?» предлагает универсальный алгоритм, отлично работающий и на HH:
- Найти официальный API.
- Если API нет — найти XHR-запросы в DevTools браузера.
- Если XHR не помог — поискать сырой JSON, встроенный в HTML.
- Если страница рендерится только в JavaScript — использовать headless-браузер.
- HTML-парсинг — последний вариант, к которому стоит обращаться, только когда всё перечисленное недоступно.
В случае HH.ru шаг номер один срабатывает почти всегда: у площадки есть зрелый REST API на api.hh.ru с документацией. Это снимает основные риски: и юридические (доступ через API не нарушает оферту), и технические (контракт API меняется реже, чем CSS-классы на странице).
Тогда зачем вообще нужны остальные шаги? Затем, что часть данных через API не отдаётся. Контакты и фотографии в резюме, расширенные карточки работодателей, рейтинги и отзывы — это всё либо платные тарифы, либо то, что скрейпится напрямую. Здесь и появляется реальная необходимость в headless и HTML-парсинге, но уже как дополнении, а не основе.
Базовое правило. Если задача решается через API — её надо решать через API. На длинной дистанции скрейпер HTML обходится дороже не потому, что его сложнее написать, а потому что его нужно постоянно чинить: HH меняет CSS-классы (например,
vacancy-serp-itemсменился наmagritte-redesignиf-test-search-result-item) каждые несколько месяцев.
Официальный API: эндпоинты, токены, поля
Документация API лежит в официальном репозитории hhru/api. Регистрация приложения происходит на dev.hh.ru, где выдаются client_id и client_secret. Для работы с публичными данными — вакансиями, регионами, справочниками — токен формально не обязателен, но без авторизации заметно жёстче лимиты. Для приватных данных, таких как полные резюме, отклики (/negotiations) или личные заметки, нужен полноценный OAuth 2.0 (Open Authorization) с обновлением access_token примерно раз в 14 дней через refresh_token.
Структура запроса
Базовый запрос на поиск вакансий выглядит так:
GET https://api.hh.ru/vacancies?text=Python&area=1&per_page=100&page=0Параметры text, area, per_page и page закрывают около 80% реальных задач. Чем точнее выставлены фильтры — тем меньше вакансий вернётся в одной выдаче, и тем дальше парсер сможет дойти до конца, не упёршись в потолок пагинации (об этом ниже).
Параметр area: 9 «стран» и 4 тысячи городов
Регионы у HH организованы трёхуровнево: страна, регион, город. Корневых стран девять, и их идентификаторы стоит держать под рукой:
| ID | Страна |
|---|---|
| 5 | Украина |
| 9 | Азербайджан |
| 16 | Беларусь |
| 28 | Грузия |
| 40 | Казахстан |
| 48 | Кыргызстан |
| 97 | Узбекистан |
| 113 | Россия |
| 1001 | Другие регионы |
Внутри России — больше 4 тысяч населённых пунктов, у каждого свой id. Москва — это 1, Санкт-Петербург — 2. Вытащить полное дерево регионов можно одним запросом к /areas; результат удобно сохранить в локальный JSON и больше не дёргать API ради справочника.
Поля вакансии
Объект вакансии возвращается уже структурированным. Чаще всего парсятся следующие поля:
| Поле | Тип | Что содержит |
|---|---|---|
id | string | Идентификатор; формирует ссылку hh.ru/vacancy/<id> |
name | string | Название позиции |
employer | object | id и name работодателя |
area | object | id и name региона |
salary | object | from, to, currency, gross (true=до НДФЛ) |
experience | string | «noExperience», «between1And3» и т. д. |
schedule / employment | string | График и тип занятости |
key_skills | list | Список навыков, заявленных вакансией |
snippet | object | Короткий requirement + responsibility |
description | string | Полное описание (HTML, требует очистки) |
published_at | string | ISO-8601, ключ для инкрементальной выгрузки |
Особое внимание стоит уделить полю salary. Зарплата может быть указана в RUB, USD, EUR или UAH, при этом флаг gross определяет, заявлена ли сумма «грязными» или «на руки». Для адекватной аналитики оба значения обычно нормализуют в рубли «после НДФЛ» по текущему курсу. Именно так это сделано в открытом проекте hh_research — там же показан вариант с предсказанием зарплаты для вакансий, в которых она не указана.
Семантика поиска через text
Параметр text — это не просто строка, а мини-язык запросов. Помимо привычного text=Python, поддерживаются:
text=NAME:python— поиск только в названии вакансии;text=COMPANY_NAME:Яндекс— поиск только по работодателю;text=DESCRIPTION:django— поиск только в теле описания;text=("QA" OR "Тестировщик") NOT ("Junior" OR "Стажер")— булева алгебра с группировкой;text=!python— точное совпадение, без морфологии.
Эта возможность существенно сокращает количество шумных совпадений. На наивный запрос text=Python выдача легко возвращает «Senior Analyst, базовое знание SQL, Python будет плюсом», что прекрасно описано в кейсе бота «Аврора»: автор пишет, что с обычным запросом получает «500 вакансий не по теме» при поиске «Python Developer без опыта». Решение там оказалось гибридным: сначала идёт /resumes/{id}/similar_vacancies, потом — обычный /vacancies, и переключение происходит бесшовно при исчерпании первого источника.
Лимиты и подводные камни
Любой парсер HH рано или поздно упирается в один из четырёх лимитов. Знание этих чисел экономит больше времени, чем любая оптимизация кода.
Глубина пагинации: 2000 записей на запрос
Это самое жёсткое ограничение. page может принимать значения 0–19, per_page — до 100, итого по любому одному набору фильтров возвращается максимум 2000 записей. Запрос «text=Python&area=113» (Python по всей России) почти всегда упирается в этот потолок, и оставшиеся 5–10 тысяч вакансий просто не достать.
Решение здесь не техническое, а методологическое: дробить запрос. Вместо одного «Python по России» делается серия — по регионам, по дате публикации, по уровню зарплаты, по профессиональным ролям. Каждая узкая выборка возвращает свои 2000, и в сумме покрытие получается полным. Именно поэтому в зрелых парсерах (например, в hh_research) есть параметр professional_roles и явное разбиение по area — это не оптимизация, а необходимое условие полноты.
Скорость запросов: ~30 RPS теоретически, 5–10 RPS на практике
Документация заявляет около 30 запросов в секунду к API. На длинных дистанциях устойчиво проходит 5–10 RPS, особенно без авторизации. На скрейпинге веб-страниц лимит ниже: по эмпирическим данным открытых проектов, выше 3–5 RPS быстро срабатывает временный бан по IP. Сам автор проекта IlyaKovalev/hh.ru-parser упоминает, что превышение 30 запросов в минуту с одного IP уже может квалифицироваться как DDoS — возможно, цифра спорная, но практика подтверждает: жадный парсер живёт от часа до суток.
Контакты в резюме: 120 в сутки на аккаунт
Это лимит самого сайта, и обходить его технически — значит идти против правил площадки. Просмотр контактов в резюме (телефон, email) ограничен 120 единицами в сутки на один авторизованный аккаунт, что подтверждается, в частности, пресетом Datacol под HH. При интенсивном парсинге аккаунт блокируется, и второй раз уже не разблокируется.
HTTP-коды и что они значат
| Код | Причина | Что делать |
|---|---|---|
| 200, но пустой массив | Селекторы устарели, JS не отработал, антибот вернул заглушку | Перейти на API или headless-браузер |
| 400 Bad Request | Кривой синтаксис text=, неэкранированные кавычки | Упростить запрос, экранировать символы |
| 403 Forbidden | Нужен токен или превышены права | Авторизация через OAuth, проверка scope |
| 429 Too Many Requests | Превышен RPS | Читать заголовок Retry-After, делать экспоненциальный backoff |
| 503 Service Unavailable | Временная нагрузка на API | Повтор через 5–10 секунд, не чаще |
Особенно коварен случай «200 OK, но списки пустые». Именно с него начинаются почти все вопросы новичков на Хабр Q&A: парсер бодро пишет «Парсинг страницы 1, 200, Парсинг страницы 2, 200…», а на выходе ничего нет. Причина почти всегда одна: контент рендерится JavaScript, а в исходном HTML сидят шаблонные плейсхолдеры вроде {{ salary.diffCompensation }}, которые BeautifulSoup честно вычитывает как текст.
Антибот-защита и техники обхода
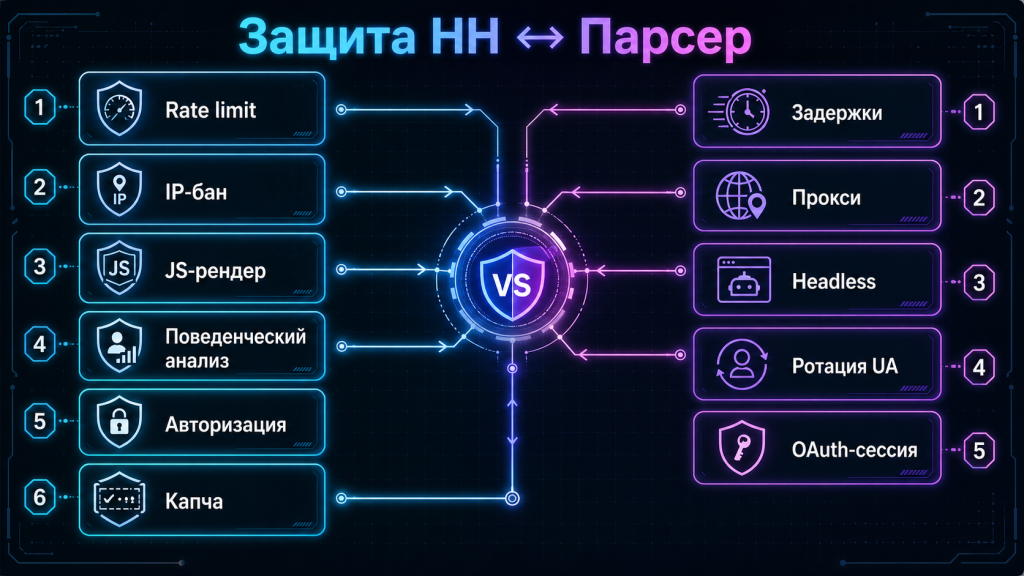
HeadHunter применяет многослойную защиту, и в большинстве случаев она настроена не на полный запрет автоматизации (это сломало бы сторонние интеграции), а на отсечение жадных и неаккуратных парсеров.
Что используется на стороне HH
- Rate limiting — лимит запросов на IP и токен, со снижением приоритета при превышении;
- User-Agent фильтрация — стоп-лист стандартных
python-requests/2.x; - Поведенческий анализ — скорость кликов, отсутствие скролла, нечеловеческая регулярность запросов;
- JS-проверки — часть контента доступна только после рендера;
- CAPTCHA — при подозрительной активности;
- Honeypot-элементы — скрытые поля, которые видит только бот;
- Лимит глубины поиска — те самые 2000 записей.
За 2024–2025 годы HH также начал ограничивать запросы из ряда дата-центров (AWS, GCP), что превратило выбор провайдера прокси из чисто технической задачи в операционно значимую. На первых этапах разработчики используют пул бесплатных прокси, но по мере роста проекта такой подход неизбежно ломается: бесплатные адреса либо в чёрном списке, либо отдают мусор.
Чем отвечает парсер
Самый недооценённый приём — задержки. Случайная пауза в 3–7 секунд между запросами и экспоненциальный backoff при 429 закрывают примерно 70% типичных банов без всякого прокси. Только когда этого недостаточно, в дело идёт ротация IP — и в крайних случаях TOR, как в проекте IlyaKovalev: там парсер генерирует случайное число от 1 до 10, делает ровно столько запросов и меняет выходную ноду TOR. Подход спорный (TOR медленный, и часть нод HH просто блокирует), но архитектурно интересный.
| Защита | Что делает HH | Что делает парсер |
|---|---|---|
| Rate limit | 429 при превышении | Случайные задержки, экспоненциальный backoff, чтение Retry-After |
| IP-бан | Временная блокировка | Ротация прокси, пул из 10–50 адресов |
| UA-фильтр | Возврат заглушки | Полный набор браузерных заголовков, ротация User-Agent |
| Поведенческий анализ | Капча или бан | Headless-браузер с случайным таймингом, скроллом и движением мыши |
| JS-рендер | Контент только после JS | Selenium / Playwright; чтение page_source после события load |
| Авторизация | Без сессии — обрезанный набор полей | Сохранение cookies, переиспользование сессии |
Современные методы детекции — отдельная история. HH пока не использует их в полную силу, но крупные сервисы уже умеют отличать клиента по TLS-fingerprint (JA3, JA4) и порядку HTTP/2-заголовков. Стандартный requests в Python имеет узнаваемый JA3, не совпадающий с Chrome, и поэтому в чувствительных проектах используют библиотеку curl_cffi с имперсонацией Chrome. Для обхода browser-fingerprinting (Canvas, WebGL, AudioContext) применяют undetected-chromedriver или puppeteer-extra-plugin-stealth. Парсеру HH это пригодится не сегодня, но когда понадобится — оно понадобится сразу и навсегда.
Резюме: правовая красная линия
Здесь начинается зона, где техника отходит на второй план, а на первый выходит закон. Резюме на HH — это персональные данные, и их массовый сбор без согласия субъекта подпадает под ФЗ-152 «О персональных данных». Поправка 152-ФЗ, статья 10.1 (введена в 2021 году), уточнила: даже данные, сделанные субъектом «общедоступными», требуют отдельного согласия на распространение. Просто публикация резюме на hh.ru не равна разрешению копировать его в чужую базу.
Прецедент по теме известный: дело № А40-18827/2017, ВКонтакте против «Дабл Дата». Суд признал, что социальная сеть имеет право защищать базу данных пользователей по статье 1334 ГК РФ — это прямо применимо к HH как к организованной базе резюме. Аналогичные иски от HeadHunter теоретически возможны, и оферта площадки прямо запрещает массовый автоматический сбор.
В цифрах риски выглядят так:
- Штраф юридическому лицу за нарушение ФЗ-152 — от 300 до 700 тысяч рублей за первое нарушение, до 18 миллионов при повторном массовом;
- Иск о компенсации со стороны площадки — до 5 миллионов рублей по статье 1334 ГК;
- Уголовная ответственность для должностных лиц по статье 137 УК РФ — до двух лет лишения свободы.
Это не предотвращает парсинг сам по себе, но превращает его из «упражнения для пятницы» в задачу с реальной юридической ответственностью. Стандартное практическое разделение выглядит так: вакансии можно собирать через API в исследовательских и личных целях. Резюме — нельзя массово ни через API, ни через скрейпинг, кроме случая корпоративного тарифа HH с явным согласием. Если задача — анализ рынка труда без идентификации кандидатов, разумной альтернативой служит государственный портал «Работа России» с открытым API без жёстких ограничений.
Короткое правило. Вакансии — публичные данные о юридических лицах, парсинг разрешён в рамках API. Резюме — персональные данные физических лиц, массовый парсинг запрещён.
Архитектура промышленного парсера
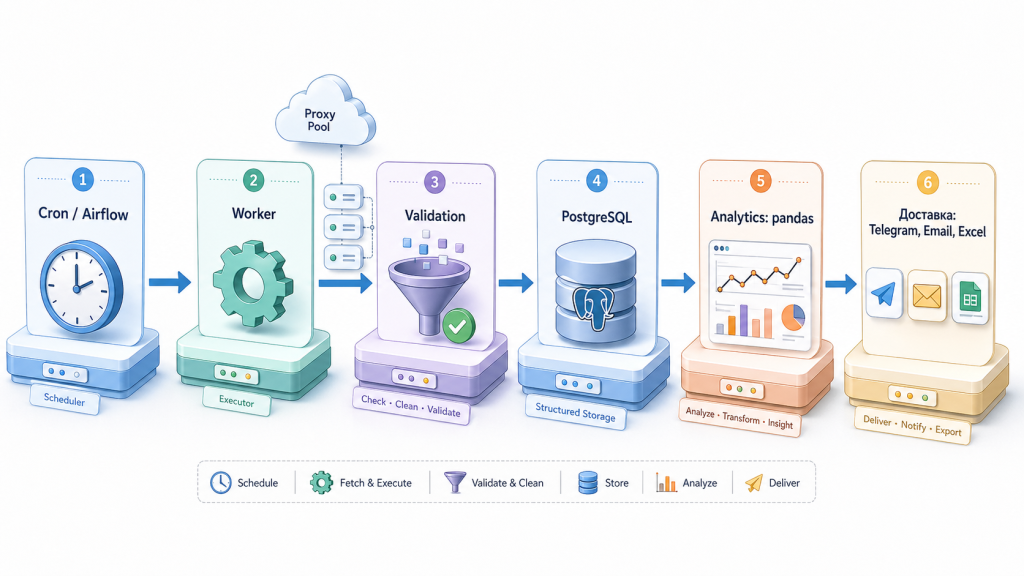
На первых этапах парсер пишется как один скрипт: запрос, цикл, сохранение в CSV. По мере роста проекта такой подход становится неудобным сразу по нескольким причинам: один баг в середине цикла теряет всю выгрузку, повторный запуск ничего не помнит, обновлений нет, ошибки молча проглатываются. Зрелая архитектура решает эти задачи разделением слоёв.
Минимально достаточный пайплайн
- Планировщик — Cron, Airflow или встроенные Cron Jobs облачного хостинга. Запускает выгрузку по расписанию.
- Воркер — собственно код парсера. Может работать в одном процессе или в кластере, при необходимости через прокси-пул.
- Слой валидации — нормализация зарплат (USD/EUR в рубли, gross в net), очистка HTML-тегов из
description, дедупликация поid. - Хранилище — для прототипа достаточно SQLite, для продакшна обычно PostgreSQL. Архивные снимки удобно класть в Parquet.
- Аналитика — pandas, Jupyter, BI-дашборд. Здесь же живут модели предсказания зарплат и кластеризация навыков.
- Доставка — Telegram, email, Excel-выгрузка, REST-эндпоинт для внешних потребителей.
В кейсе hh.ru_pars от DarkDarW хранилище реализовано на SQLite, веб-интерфейс — на Flask, всё запускается через docker-compose. Это рабочий минимум для одного исследователя. На уровне сотен пользователей такой стек ломается, и здесь начинается зона PostgreSQL и асинхронных очередей.
Когда нужен инкрементальный парсинг
Большинство открытых проектов описывают полный сбор: «выкачали всё, посчитали статистику». В реальной задаче гораздо чаще нужен инкремент: «что появилось со вчера». В API HH есть параметры date_from и date_to, и поле published_at у каждой вакансии — но архитектура incremental loader редко разбирается в туториалах. Минимум, который должен быть: таблица «последний обработанный published_at на запрос», и запрос идёт от этой точки. Такой подход снимает 90% нагрузки и позволяет держать актуальную базу при минимальном RPS.
Очередь задач и FOR UPDATE SKIP LOCKED
Если парсер не только собирает данные, но и совершает действия (отклики на вакансии, отправка писем) — нужна полноценная очередь. Хороший пример — кейс «Авроры»: бот в Telegram при нажатии «Старт» находит 100 вакансий, на каждую генерируется письмо через LLM (5–10 секунд) и делается POST в /negotiations (1–2 секунды). Синхронный отклик блокирует event loop полностью.
Решение через PostgreSQL-очередь использует ключевую SQL-конструкцию:
UPDATE application_queue SET status = 'processing'
WHERE id = (
SELECT id FROM application_queue
WHERE status = 'pending'
ORDER BY created_at
LIMIT 1 FOR UPDATE SKIP LOCKED
)
RETURNING *;Транзакция атомарно находит свободную задачу, блокирует её, а если запись уже занята другим воркером — пропускает и берёт следующую. Это позволяет нескольким инстансам бота работать с одной таблицей без конфликтов и без сложной координации. Даже если воркер упадёт посреди обработки, статус останется в processing, и при перезапуске задача восстановится из БД, а не пропадёт.
Кейсы реальных проектов
hh_research: исследование рынка через API
Open-source проект Александра Капитанова — это полноценный исследовательский тулкит на Python. Архитектура простая: настройка через JSON-конфиг (text, area, per_page, professional_roles), многопоточный сбор через API, нормализация зарплат с пересчётом USD/EUR в рубли и gross в net, сохранение в DataFrame и далее в CSV. Поверх этого — статистика по медиане, средней и распределению зарплат, частотный анализ ключевых навыков и предсказание зарплаты для вакансий, где она не указана. Проект собрал около 120 звёзд на GitHub — ориентир по качеству и зрелости кода.
gaisin/hh_parser: частотный анализ навыков
Маленький демо-парсер, написанный ещё в 2017 году, но именно он показывает, насколько быстро устаревают данные. На запрос «python» по всей России (area=113) в выборке из 2000 вакансий чаще всего встречались: python (493), linux (248), git (157), sql (153), postgresql (132), javascript (114), java (106), django framework (97), mysql (93), c++ (80). Сегодня в топе появился бы Kubernetes, Golang, MLOps, LLM — навыки, которых в 2017 году в выдаче практически не было. Это иллюстрирует data drift: модель, обученная на старых частотах, к актуальному рынку относится плохо.
Friztutu/hh.ru_scraper: автоотчёты с графиками
Проект собирает CSV, текстовый автогенерируемый отчёт и графики распределения зарплат. По данным репозитория, парсинг 100 страниц (около 2000 вакансий) занимает примерно час — это разумный ориентир для скрейпинга через requests без прокси и многопоточности. Если поднять конкурентность до 10 потоков и переехать на API, ту же задачу реально решить за 3–5 минут.
«Аврора»: гибридный поиск + LLM-отклики
Telegram-бот, описанный в материале на Хабре, объединяет три нетипичных для HH-парсеров приёма: гибридный поиск через similar_vacancies с переключением на /vacancies, генерацию персонализированных писем через Gemini и асинхронную очередь на PostgreSQL. Конечный автомат настройки реализован через ConversationHandler из python-telegram-bot, и автор отдельно подчёркивает, что его отладка заняла больше времени, чем сам поиск. Это типично для таких систем: техника парсинга обычно проще, чем UX и обработка ошибок.
IlyaKovalev/hh.ru-parser: парадокс TOR
Незавершённый проект 2019 года, интересный самим подходом: запросы идут через torsocks, причём с дополнительной случайностью — скрипт выбирает случайное число от 1 до 10, делает ровно столько запросов и меняет выходную ноду. Архитектурно это интересный вариант обхода IP-бана без коммерческих прокси, но на практике скорость TOR делает его пригодным только для небольших исследовательских выгрузок. Для парсинга 100 тысяч вакансий через TOR уйдут сутки.
Готовые сервисы и no-code инструменты
Не каждый, кому нужны данные с HH, готов писать код. Для таких случаев существует целый сегмент готовых решений — от настольных парсеров до полностью управляемых сервисов с API доступа к выгрузкам. Сравнительная таблица помогает выбрать по типу задачи:
| Сервис | Тип | Что отдаёт | Особенности | URL |
|---|---|---|---|---|
| hh_research | Open-source библиотека (Python) | CSV с вакансиями, статистика, графики | Бесплатно, требует настройки и Python | github.com/hukenovs/hh_research |
| Авто-Парсер.ру | SaaS под ключ | Ежедневные выгрузки в CSV/Excel + REST API с ключом | Разделитель CSV — вертикальная черта, обновление после 06:00 МСК | auto-parser.ru/parser_hh_ru |
| Datacol (web-data-extractor) | Настольное приложение | CSV, Excel, выгрузка в WordPress, Joomla, DLE | Демо хранит первые 25 записей; для резюме нужна авторизация в браузере | web-data-extractor.net/parser-vakansij-hh-ru |
| ParsingMaster | Заказной парсинг | Данные в любом формате под задачу клиента | Услуга «под ключ», интеграция в CRM/CMS | parsingmaster.com/parsing-hh |
| Octoparse / ParseHub | No-code парсеры | Структурированные данные через визуальный конструктор | Подходят для разовых задач, плохо масштабируются на API | octoparse.com / parsehub.com |
Выбор между этими вариантами обычно сводится к трём вопросам. Нужны ли данные на регулярной основе? Если да — SaaS экономит больше, чем стоит. Допустимо ли держать инфраструктуру самому? Если нет — заказной парсинг или подписка предпочтительнее. Какая часть задачи приходится на аналитику, а какая на сбор? Если 80% работы — это анализ, имеет смысл купить готовую выгрузку и сосредоточиться на интересном; если 80% — это автоматизация бизнес-процесса, лучше писать своё, потому что любой готовый сервис рано или поздно упрётся в специфические требования.
Типичные ошибки и как их избежать
Большая часть граблей в парсинге HH повторяется из проекта в проект. Вот короткий перечень того, что чаще всего ломает выгрузки.
- Старт со скрейпинга вместо API. Самая частая и дорогая ошибка. На API HH хорошая документация и предсказуемое поведение; HTML меняется каждые 2–3 месяца, и парсер на BeautifulSoup тоже придётся менять каждые 2–3 месяца. Скрейпер пишется быстрее, но обходится дороже.
- Игнорирование лимита 2000 записей. Парсер «доходит» до 19-й страницы, видит пустой ответ и думает, что собрал всё. На самом деле ушло полторы тысячи вакансий из десяти. Решается дроблением запроса по фильтрам.
- Отсутствие задержек. Запрос в цикле без
sleepпочти гарантированно даёт 429 в течение часа. Случайные паузы в 1–3 секунды и экспоненциальный backoff после первого 429 закрывают вопрос на 90%. - Парсинг рендеримой страницы через requests. Классический симптом — ответ 200, в коде
{{ salary.diffCompensation }}, на странице ничего нет. Лечится либо переездом на API, либо переходом на Selenium/Playwright. - Хранение в одном плоском CSV. На 10 тысячах записей удобно, на 100 тысячах уже мучительно, на миллионе — невозможно. SQLite спасает до миллиона, после нужен PostgreSQL.
- Отсутствие нормализации зарплат. В выгрузке смешаны RUB, USD, EUR, gross и net, и медианная зарплата получается бессмысленной. Все значения нужно приводить к рублям после НДФЛ до загрузки в аналитику. Ошибка в нормализации одного поля искажает все производные метрики.
- Отсутствие дедупликации. Одна вакансия может быть спарсена дважды, если запросы пересекаются по фильтрам.
idвакансии — естественный первичный ключ, и UNIQUE-индекс по нему предотвращает дубли на уровне БД. - «Вечные» вакансии. HR-отделы переоткрывают одну и ту же позицию каждые 30 дней, чтобы держать её в топе выдачи. Получается, что новых вакансий с компании 50, а реальных — 5. Простой эвристический фильтр (одинаковое название и описание у одного работодателя) убирает большую часть шума.
Короткий чек-лист перед запуском в продакшн. Запрос разбит по фильтрам? Зарплаты нормализованы в одну валюту и один режим (gross/net)? Включён бэкофф на 429? Есть UNIQUE по
vacancy.id? Есть инкрементальный парсинг поpublished_at? Если хотя бы на один пункт ответ «нет» — продакшн преждевременен.
Парсинг HH хорошо иллюстрирует общий принцип: техническая часть редко бывает самым сложным. Самое сложное — это не «как достать данные», а «как сделать так, чтобы выгрузка не превратилась в постоянный источник тушения пожаров». Грамотная архитектура и опора на официальный API превращают парсер из расходного скрипта в работающий инструмент анализа рынка труда — и именно в этом разница между прототипом и продакшном.


